This post briefly introduces the textline extraction pipeline used in the project.

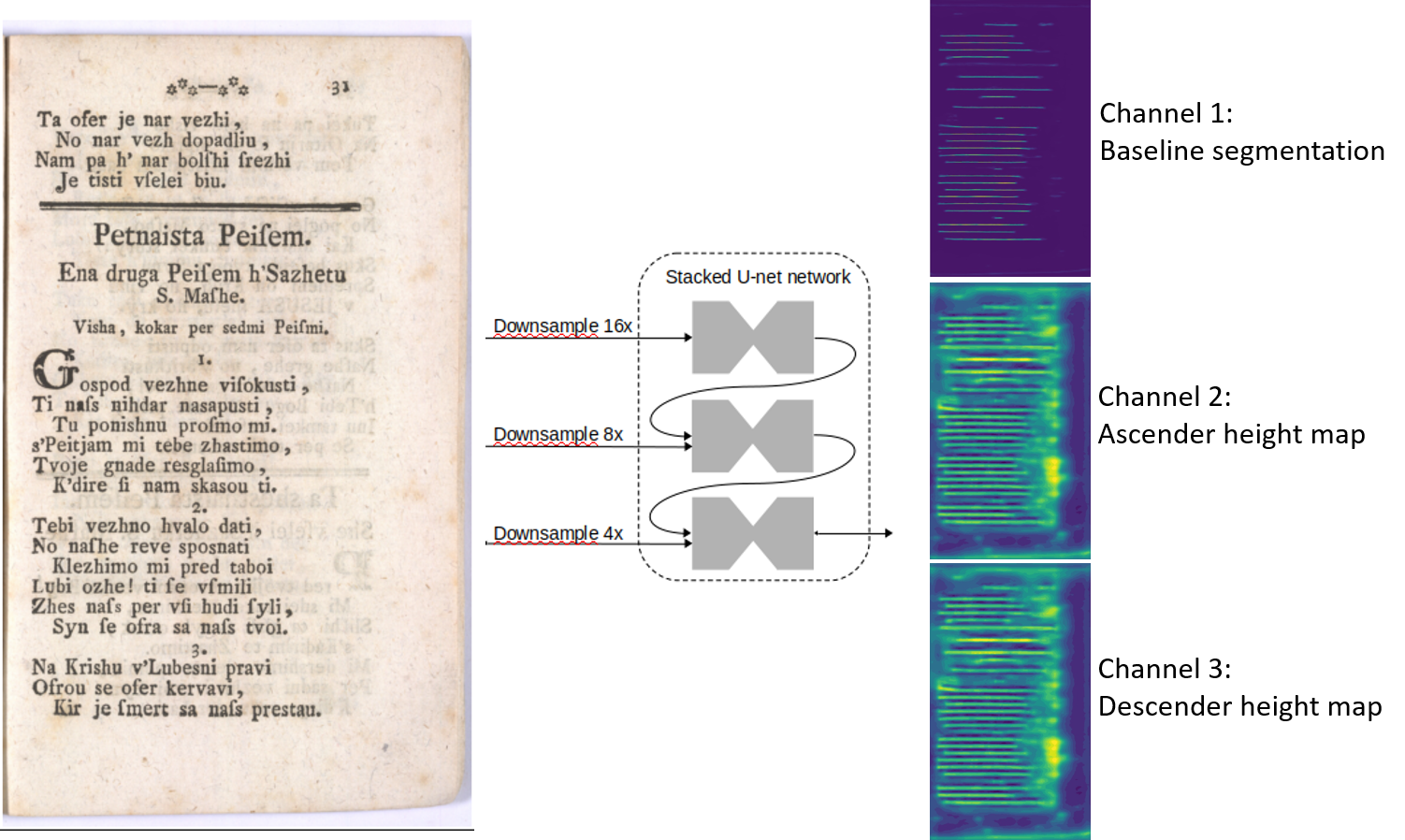
Before OCR can be applied to a document page, textlines need to be efficiently detected and extracted. To fully characterize a textline, two pieces of information are required. First, baseline coordinates specify the location of the textline. Second, height of the font ascenders and descenders further specify the area that needs to be cropped to contain all the information without overshooting into neighbouring textlines. Knowing these parameters, a full textline bounding box can be easily computed. This is especially suitable when working with the standard PAGE XML format.

To efficiently predict these values for an input document page, we employ a convolutional neural network with encoder-decoder architecture. This network analyses the page image under three different resolutions to maintain robustness across different page layouts and font sizes. At each resolution step, the outputs from previous steps are concatenated to the current input as seen in the picture.
On the output layer of the network, three values are predicted for each pixel. The probability of the pixel containing a baseline, the estimated ascender height of the font in this pixel and, analogically, the estimated descender height. These maps are then processed using simple thresholding and connected component analysis on the baseline probability channel. The font height values for each detected line are computed as median of the height predictions on the corresponding baseline pixels.
In some cases where the page has been bent before being scanned or when hand-written textline is crooked, simple cropping of the bounding box leads to images that contain more than one textline and are therefore unsuitable for OCR methods. Therefore, in such cases, textline unfolding is performed as an additional post-processing step. This elastically transforms the image using normals of the detected baseline.

Thus, even sub-optimally scanned document pages with challenging layout and variety of different fonts and headings can be fully automatically parsed into cropped textlines.